From four servers to a platform
Written by Wim Tilburgs & Kamal — a human and his Claude AI, together.
This is the honest reconstruction of a few intense days, written right after the migration: the mistakes, the choices and the why — not a polished story after the fact. Anything that could help an attacker (addresses, keys, internal names) we deliberately left out; this is about the story and the architecture, not the master key.

The gist. We built a production Kubernetes platform and migrated a high-traffic website — in three days. But those three days don’t stand alone: they’re the crown on nine months in which we built something else entirely — not the car, but the factory. A way for a human and an AI to work together: skills, memory, connections, trust. The migration flew because the foundation underneath was already there. And best of all: we now understand every layer ourselves.
Where we started: pets, not cattle
JLAM — Je Leefstijl Als Medicijn (“Your Lifestyle As Medicine”) — runs on software. A high-traffic website with tens of thousands of readers, a membership system, payment flows, a newsletter, a community. Until recently all of that lived on four virtual machines we had set up by hand. Log in, install a package, tweak a config file, hope you still understand it six months later.
In the DevOps world this is the “pets versus cattle” problem. A pet server has a name, you nurture it personally, and when it gets sick you sit at its bedside. Cattle are anonymous and interchangeable: if one falls over, an identical one automatically takes its place.
Our servers were pets. And that hurt at exactly the wrong moments:
- The CI/CD pipeline that rolled out new code ran on the same server as the production website. Every build filled the disk a little more — until one day it was full.
- A fault in an add-on component once made a log file explode, after which the whole server toppled. One part dragged down the rest.
- Every change was manual work. Manual work isn’t repeatable, and what isn’t repeatable isn’t reliable.

We wanted cattle. A platform where a broken part is replaced automatically, where every change goes through code and review, and where the pipeline does not live on the production server.
The building blocks: container, Kubernetes, cluster
Before I tell you what we built, three terms — because without them the rest is gibberish.
A container is an application plus exactly the bits it needs, packed into one thin, portable block. Unlike a virtual machine, a container doesn’t drag a whole operating system along; it shares the one underneath. So it starts in seconds and runs the same everywhere — on your laptop and in production.
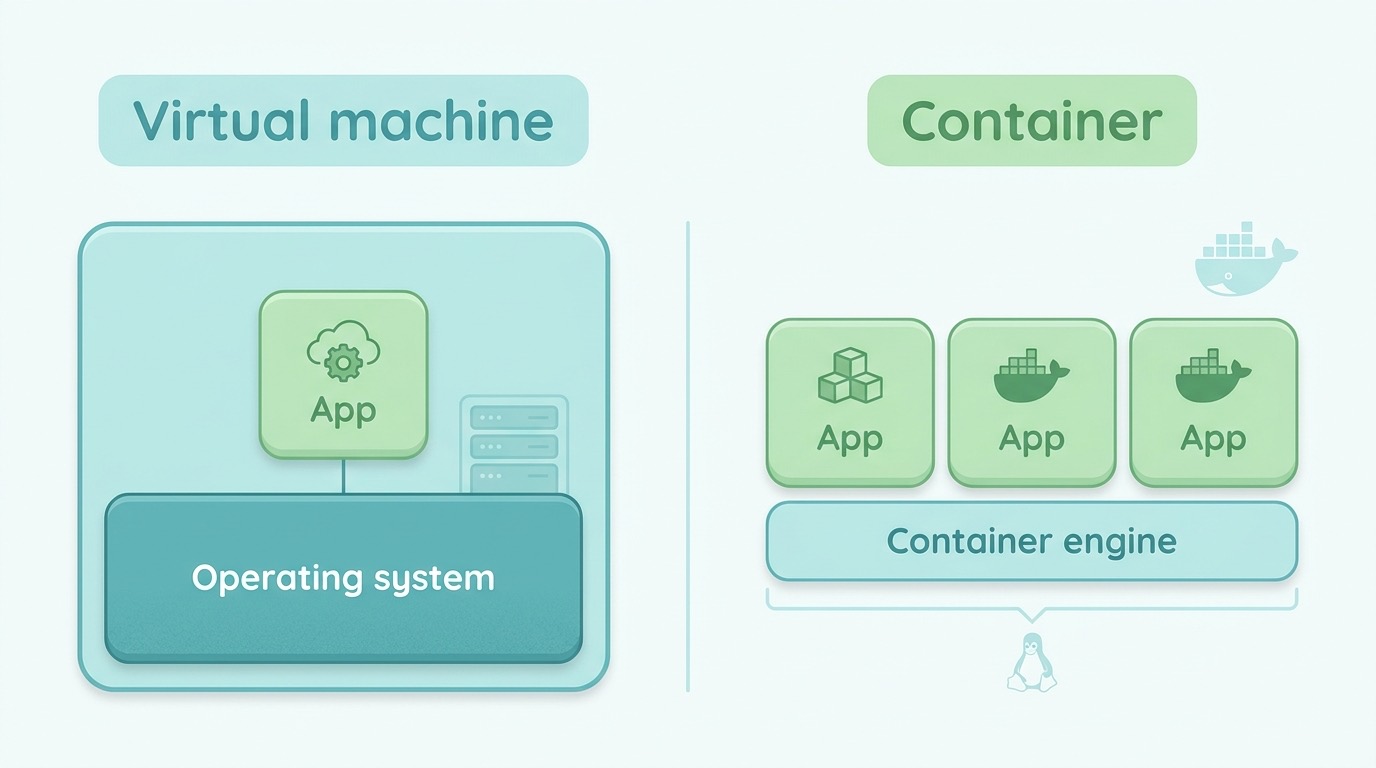
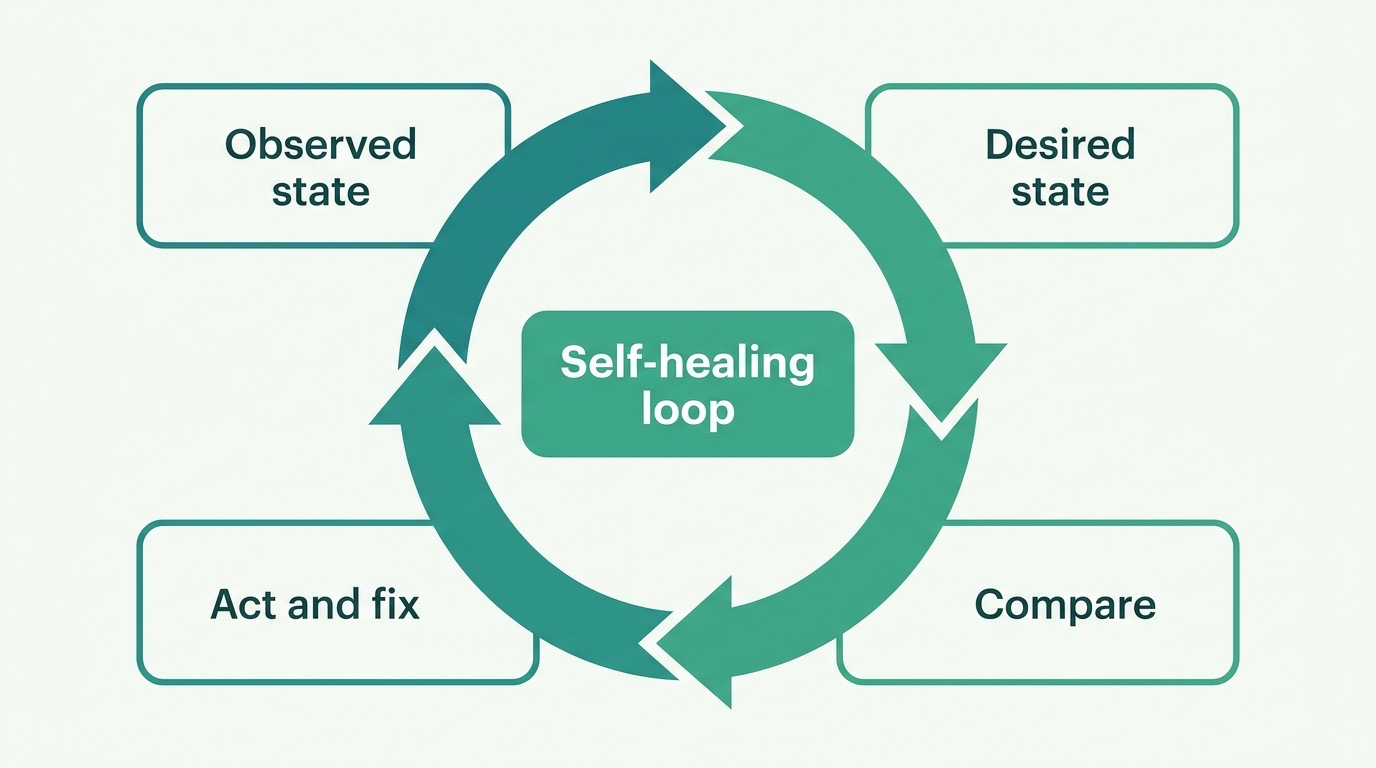
Kubernetes is the conductor that directs hundreds of those containers. You don’t tell Kubernetes how — you tell it what: “I always want four copies of the website running.” If one crashes, Kubernetes starts a new one by itself. That’s the reconciliation loop: the system relentlessly compares the desired state with the actual one, and repairs the difference. Self-healing, without anyone having to get out of bed at night.
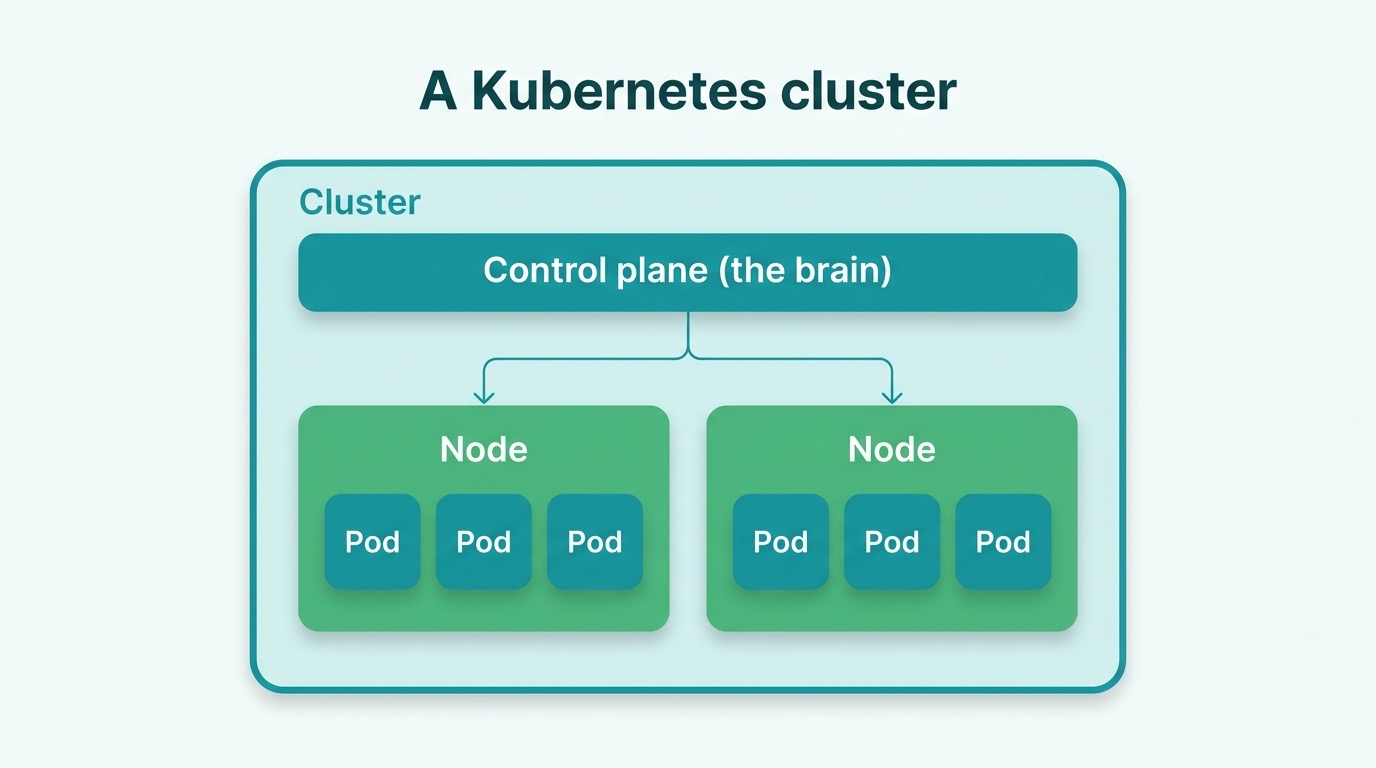
A cluster is a group of machines that Kubernetes runs on. At the top the control plane (the brain that decides), below it the nodes (the workhorses that run the containers). We chose managed Kubernetes at Scaleway (their Kapsule service): the provider maintains the control plane, we only manage the workhorses. One worry less.
The architecture we chose
We could have kept it simple: one cluster, everything inside. But a platform meant to grow — and to one day survive an audit — deserves a separation of concerns.
So there are now two clusters:
- A tooling cluster (the shared workshop) for everything that serves the other clusters: the build machinery, central management.
- A production cluster that carries the actual apps.
Those two live in separate virtual private networks (VPCs) — three in total, with a dedicated space reserved for development. The idea: one compromised component must not automatically reach the rest. Network isolation isn’t a luxury, it’s the first line of defence.
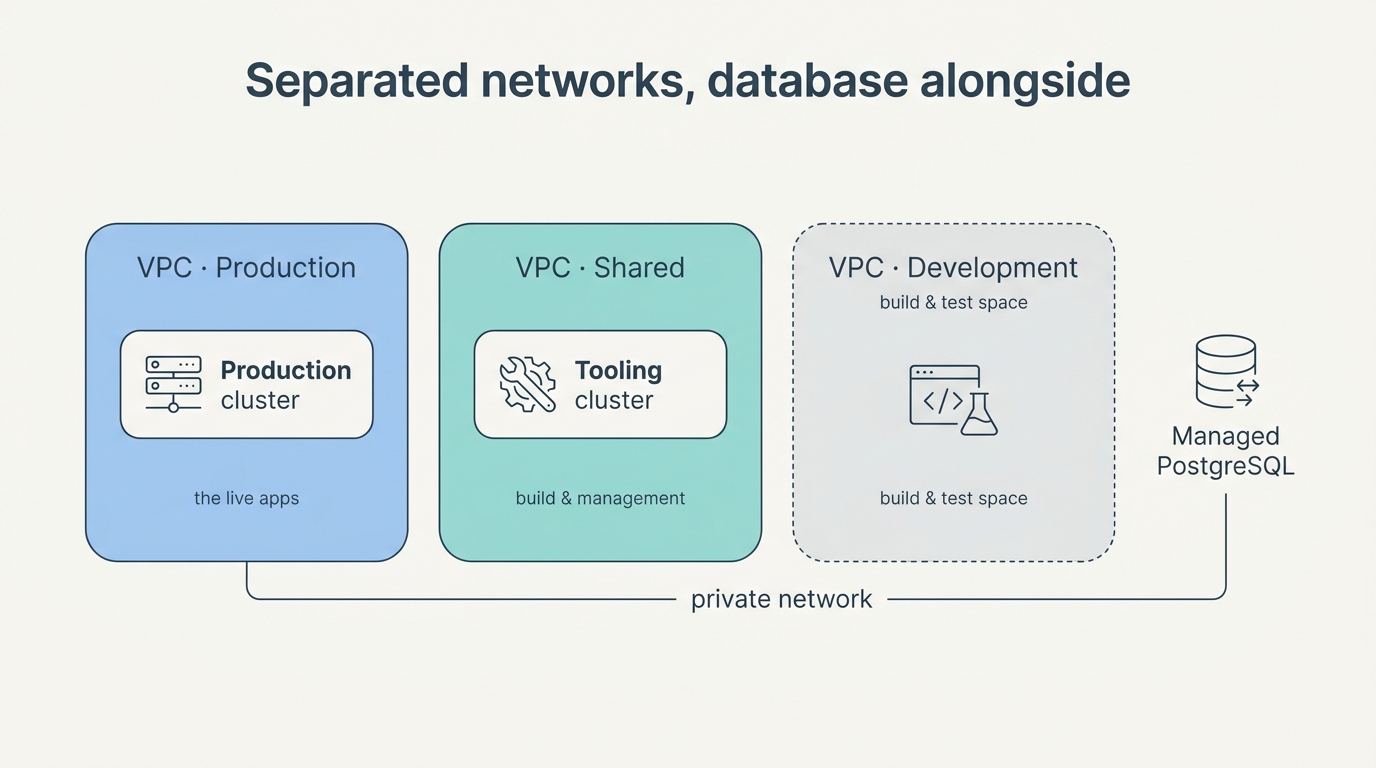
Deliberately outside the cluster: the database. Our PostgreSQL runs as a managed service alongside, not as a container inside. A database in a cluster is possible, but it puts (literal) data at risk the moment the cluster hiccups. The apps in the cluster talk to that managed database over the private network — fast, and not exposed to the public internet.
From “built” to “live by itself”: GitOps
This is the heart of the story. How does code actually reach production?
The old-fashioned way: an engineer logs into the server and does something. The modern way is called GitOps, and the principle is astonishingly simple: the truth lives in Git. Nobody mutates the cluster by hand. Instead you describe the desired state in files in a Git repository, and a watcher — in our case ArgoCD — keeps the cluster moving relentlessly towards it. If the cluster drifts, ArgoCD pulls it back to what’s in Git.
The lovely consequence: every change to production is a Git commit. Reviewable, reversible, with a name attached. Your production history is your Git history.
We built the whole chain so that code goes live fully automatically:
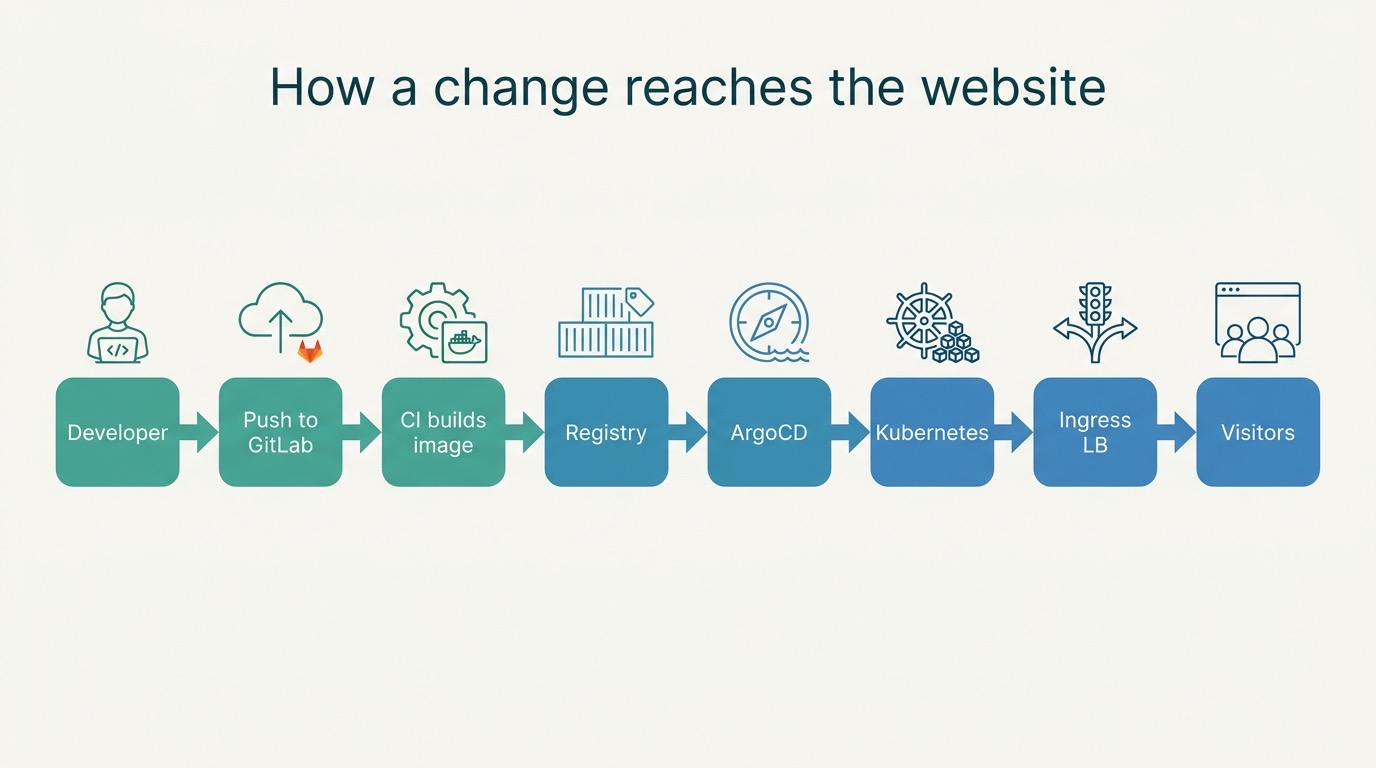
- A change is merged.
- CI builds a container image and puts it in the registry.
- A robot (the image-updater) sees the new version and writes it to a separate branch.
- A scheduled step automatically opens a merge request for it and sets “merge once the tests are green”.
- ArgoCD sees the merged change and rolls it out to the cluster.
While writing this piece we proved that chain end-to-end twice with real changes: merged, built automatically, promoted, and live on the cluster — without a single manual step. That is the difference between “we have servers” and “we have a platform”.
Getting an app cluster-ready — and the lesson that hurt
Moving an application to Kubernetes is more than stuffing it into a container. It has to be stateless (no data on the local disk you can’t lose), read its configuration from the environment, and receive its secrets safely.
That last part taught us the sharpest lesson of the whole migration.
Secrets — API keys, passwords — don’t belong in Git or in an image. We deliver them through a secrets vault (1Password) that an operator in the cluster turns into what the app needs. Neat. Except that the list of secrets had been moved over by hand during the migration. And with manual work, you forget things.
The result: a few environment keys hadn’t come along in the move. The webinars page stayed empty and a couple of background tasks were switched off — without the site showing a single error.
This is the treacherous thing about well-built software: it degrades gracefully. A missing key doesn’t crash the site; it quietly switches off a feature. No red page, no alarm — exactly the kind of gap you only spot when someone trips over it.
Except we did see it — and fast. That’s where investing in observability paid off. Sentry caught the first signals, Inngest deliberately failed hard instead of quietly carrying on, and our own tests confirmed the rest. And those alerts don’t vanish into a full inbox: they arrive live on Telegram, where we — human and AI — are essentially always watching. Part of the signals is even already picked up by an AI watchdog that immediately stages a draft fix; all I then have to do is review it and press the button. Spotted and closed within the migration windows — not silently broken in production for months.
The lesson we recorded right away: make those gaps loud instead of silent. We wrote an architecture decision and a ticket for a parity gate — a check that fails the rollout the moment an expected key is missing. And the deeper lesson: it’s not “it seems to work” that counts, but whether you actually see it. Good tooling — Sentry first, plus Inngest and real tests — is the difference between “found within an hour” and “a complaining customer a month later”.
Security: trust as little as possible
A platform that’s publicly reachable demands discipline. The principles we held to, in plain language:
- Least privilege — every component gets exactly the rights it needs, no more.
- Network segmentation — by default nothing may talk to anything; traffic is opened explicitly, not trusted implicitly.
- Secrets never in Git — they come from a vault, via an operator, and never touch the codebase.
- TLS automatically — certificates are requested and renewed by the platform; no human who has to remember an expiring certificate.
- The front door as a single controlled point — all incoming traffic runs through an ingress (Traefik with the Gateway API, in our case), not through a tangle of separate openings.
None of this is special for someone who does it daily. What’s special is that a platform forces you to do it this way — while hand-fed servers tempt you into “just quickly”.
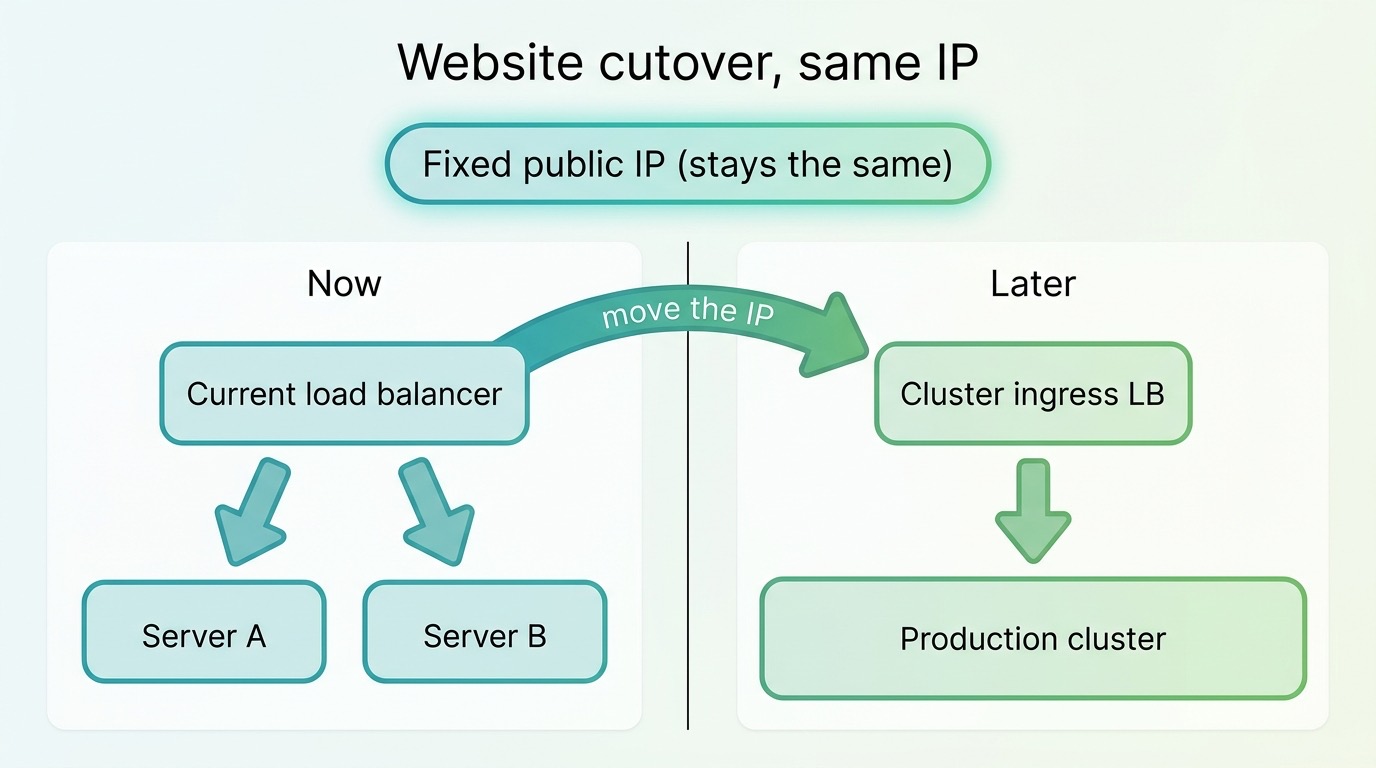
The cutover: the public address stays, only the destination changes
The scariest step was the website itself — a high-traffic, multi-tenant application — moving it from the old servers to the new cluster with zero downtime.
The trick is separating address from destination. The public IP address that visitors and DNS point to doesn’t need to change. We only moved where that address leads: from the old load balancer to the cluster’s ingress. To the outside world everything stayed the same; internally the whole destination shifted. Then we verified layer by layer — reachability, a valid TLS certificate, the database connection — and kept the old servers on hand as a fallback for a while.
What this normally costs
Time for the uncomfortable part — because this is where the story really lands. What would it cost to have this built by a hired specialist, at this quality?
Let’s be precise about what “this” is: not shoving one app into a container, but designing and building a complete platform (managed Kubernetes, two clusters, separate networks, Infrastructure-as-Code, GitOps, secrets management, automatic TLS, CI/CD, observability) and migrating a high-traffic production application to it with zero downtime — with documentation and architecture decisions on top.
The market figures (2025–2026):
- Freelance rates, the Netherlands. A senior DevOps/platform engineer here easily charges €100 to €125 an hour; an IT/technical architect sits around €116 an hour according to the 2025 Dutch freelance rate survey.12 Internationally, specialised Kubernetes freelancers go up to $140–300 an hour.3 A salaried senior in the Netherlands earns €85,000–€150,000 gross a year — which underpins those freelance rates.4
- A real migration engagement. A simple “lift one app to Kubernetes” can be done for $15,000–50,000.5 But a comprehensive engagement — architecture, build, migration and knowledge transfer, exactly our scope — lands in a published case study at $120,000 in consulting alone and $239,000 total, over 16–20 weeks with multiple consultants.6
Translated to our situation, honestly and conservatively:
One senior freelancer building this properly: roughly €40,000–€80,000 over two to four months. A specialised consultancy delivering the same — design, build, migration, handover: €100,000 or more, in line with the published case studies.
And that isn’t even the high scenario. It’s the floor of serious, like-for-like work.
We did it in three days. At night, in the quiet hours, alongside the day job. But before you write that off as magic — do read the next section. Because those three days deserve an honest explanation.
Why three days was possible — the factory, not the car
“A production platform in three days” sounds like nonsense. And if I don’t explain why it was possible, it is.
The three days were possible because in the nine months before, we built something else entirely. Not the car, but the factory.
In an earlier piece I already wrote it: don’t build the car, build the factory. That’s exactly what happened here. For nine months we invested not in one-off solutions, but in how a human and an AI work together:
- a library of skills — reusable ways of working that my AI colleague deploys per task;
- a persistent memory — so context doesn’t evaporate every session and we don’t start over each time;
- connections to real systems — an AI that doesn’t just talk but can do things: query servers, roll out code, run checks;
- and the least visible, and most important: working agreements, guardrails and trust — the shared language in which we dare to take risky steps together, with the human at the controls for everything that matters.
That’s the factory. And a factory that’s already running produces fast. The migration didn’t go fast because of faster hands — it went fast because the foundation was already there.
So the AI didn’t replace a team of consultants. It was a senior colleague sitting beside me: sketching the architecture, writing code, hunting down mistakes, and forcing me to confirm at every risky step. The decisions were mine. I pressed the production buttons. And I had to understand it myself — because I’m the one who has to carry on with it tomorrow.
That’s where the real win is, and it’s bigger than this one project:
A consultancy quotes tens to hundreds of thousands of euros for a single migration. We built a reusable capability — the next migration costs us days, not months. We didn’t buy a car; we have a factory.
The compression was in the learning and the reuse, not in skipping steps. We didn’t skip a single one. We just did them far faster — because there was always someone beside me who already knew, and because we had forged the tools to do it ourselves.
What we learned along the way
A few lessons that hold more broadly than this one project:
- Graceful degradation hides gaps. Software that falls back neatly hides faults until a user trips over them. Make missing dependencies loud — fail the rollout, not the user.
- A human has to watch the last metre. An automated check confirmed an attribute was “live” — but only when a human clicked in a real browser did the behaviour turn out to be wrong. Automation and a human eye complement each other; neither is enough on its own.
- One template for all apps. What we built for the first app, we don’t want to redo per app. The payoff of a platform is repeatability — so the chain becomes a reusable pattern.
- The shared database is a shared risk. As long as the old and the new world share the same database, a rollout in one world can briefly affect the other. Separation of concerns is never “done”.
- Cattle, not pets — in your head too. The biggest change wasn’t technical but mental: stop nursing servers, start describing systems.
Where it stands now
The platform is running. The high-traffic website is live on the production cluster, with valid TLS and a database connection over a private network. The rollout chain has been proven end-to-end twice. The secret gaps are closed and the structural improvement (the parity gate) is recorded as a decision and a ticket. The old servers stand by a little longer as a safety net, until we’re sure everything is stable.
And there’s a roadmap: generalise the rollout chain into one reusable pattern for all apps, phase out the old servers, and enforce the quality and security checks centrally.
But the core is in. From four hand-fed pets to a self-healing platform — built by a self-taught founder and his AI colleague, in three days, on top of nine months of foundation, with an understanding of every layer.
That last part isn’t a side note. It’s the whole point.
And maybe it’s also the beginning of a new kind of profession. Not the specialist who can do everything alone, but someone who — together with AI — builds a factory and keeps it running. More on that another time.
— Wim Tilburgs & Kamal
Glossary
- Container — an application plus its dependencies, packed into one portable, thin block.
- Kubernetes — the system that directs containers and guards the desired state.
- Cluster — a group of machines that Kubernetes runs on (a brain + workhorses).
- Node — a single workhorse machine in a cluster.
- Control plane — the brain of the cluster that makes decisions.
- GitOps — the practice where Git is the truth and the cluster moves towards it automatically.
- ArgoCD — the watcher that keeps the cluster in sync with Git.
- Ingress — the controlled front door through which all incoming traffic runs.
- Reconciliation loop — the relentless comparison of desired versus actual state.
- Stateless — an app that keeps no indispensable data locally and is therefore interchangeable.
- VPC — a virtual private network that isolates components from each other.
- Least privilege — the principle that every component gets as few rights as possible.
About the technology used
Want to dig deeper into the building blocks? The authoritative sources:
- Kubernetes — the official documentation. The “pets versus cattle” idea originally comes from Randy Bias; read the history of the analogy and pets vs. cattle in the Kubernetes world.
- Scaleway Kubernetes Kapsule — the managed Kubernetes service we use (with a region in Amsterdam). See the service definition — Scaleway manages the control plane — and the FAQ, which notes that nodes may simply be replaced or restarted: cattle, not pets.
- GitOps & Argo CD — Argo CD, the watcher that keeps the cluster relentlessly in sync with Git.
- Claude Code — the agentic coding tool by Anthropic that worked beside me as a senior colleague: lives in the terminal, understands the codebase, executes tasks.
Sources
Footnotes
-
TechPays — Netherlands, DevOps contract rates (freelance senior DevOps ~€85–105/hour; dataset with a limited number of data points, indicative). https://techpays.com/europe/netherlands/eng_devops/contract ↩
-
Xolo / Knab Freelance Rate Survey 2025 — overview of freelance hourly rates in the Netherlands (IT/technical architect ~€116/hour), based on a survey of ~20,000 freelancers. https://blog.xolo.io/nl/freelance-hourly-rates-insight-into-the-netherlands ↩
-
Jobbers — DevOps & Cloud Infrastructure Freelancing Rate Guide 2026 (specialised Kubernetes freelancers $140–300/hour). https://www.jobbers.io/devops-cloud-infrastructure-freelancing-aws-kubernetes-sre-rate-guide-2026/ ↩
-
Asanify — Hiring DevOps Engineers in the Netherlands 2025 (senior €85,000–120,000, lead/principal €110,000–150,000+ gross per year). https://asanify.com/blog/hiring-in-netherlands/hire-devops-engineers-in-netherlands-2025/ ↩
-
Tasrie IT — Kubernetes Migration Cost (2025 Price Breakdown) (simple migration $15,000–50,000, strongly scope-dependent). https://tasrieit.com/blog/kubernetes-migration-cost-2025-price-breakdown ↩
-
Tasrie IT — case study of a comprehensive Kubernetes migration ($120,000 consulting, $239,000 total, 16–20 weeks, multiple consultants). https://tasrieit.com/case-studies/253k-saved-kubernetes-migration-consultants-case-study ↩