Van vier servers naar een platform
Geschreven door Wim Tilburgs & Kamal — een mens en zijn Claude-AI, samen.
Dit is de eerlijke reconstructie van een paar intense dagen, direct na de migratie: de fouten, de keuzes en het waarom — geen marketingverhaal achteraf. Alles wat een aanvaller zou kunnen helpen (adressen, sleutels, interne namen) lieten we bewust weg; het gaat om het verhaal en de architectuur, niet om de loper.

De kern. Wij bouwden een productie-Kubernetes-platform en migreerden een drukbezochte website — in drie dagen. Maar die drie dagen staan niet op zichzelf: ze zijn de kroon op negen maanden waarin wij iets heel anders bouwden — niet de auto, maar de fabriek. Een manier van samenwerken tussen mens en AI: skills, geheugen, koppelingen, vertrouwen. De migratie ging razendsnel omdát het fundament eronder er al lag. En het mooiste: wij snappen nu zélf elke laag.
Waar we begonnen: huisdieren, geen vee
JLAM — Je Leefstijl Als Medicijn — draait op software. Een drukbezochte website met tienduizenden lezers, een ledenadministratie, betaalstromen, een nieuwsbrief, een community. Tot voor kort stond dat allemaal op vier virtuele machines die we met de hand hadden ingericht. Inloggen, pakketje installeren, configuratiebestand aanpassen, hopen dat je het over een half jaar nog snapt.
In de DevOps-wereld heet dat het “pets versus cattle”-probleem. Een huisdier-server heeft een naam, je verzorgt ‘m persoonlijk, en als ‘ie ziek wordt zit je aan z’n bed. Vee is anoniem en inwisselbaar: valt er één om, dan komt er automatisch een identieke voor in de plaats.
Onze servers waren huisdieren. En dat deed pijn op precies de momenten dat het niet uitkwam:
- De CI/CD-pijplijn die nieuwe code uitrolde, draaide op dezelfde server als de productie-website. Bij elke build vulde die de schijf verder — tot ‘ie een keer vol zat.
- Een storing in een bijgeplaatste component liet ooit een logbestand exploderen, waarna de hele server omviel. Eén onderdeel sleurde de rest mee.
- Elke wijziging was handwerk. Handwerk is niet herhaalbaar, en wat niet herhaalbaar is, is niet betrouwbaar.

We wilden naar vee. Naar een platform waar een kapot onderdeel vanzelf wordt vervangen, waar elke wijziging via code en review loopt, en waar de pijplijn níét op de productieserver woont.
Even de bouwstenen: container, Kubernetes, cluster
Voordat ik vertel wat we bouwden, drie begrippen — want zonder die drie is de rest abracadabra.
Een container is een applicatie plus precies de spullen die ze nodig heeft, ingepakt in één dun, draagbaar blok. Anders dan een virtuele machine sleept een container geen heel besturingssysteem mee; hij deelt dat met de machine eronder. Daardoor start ‘ie in seconden en draait ‘ie overal hetzelfde — op je laptop én in productie.
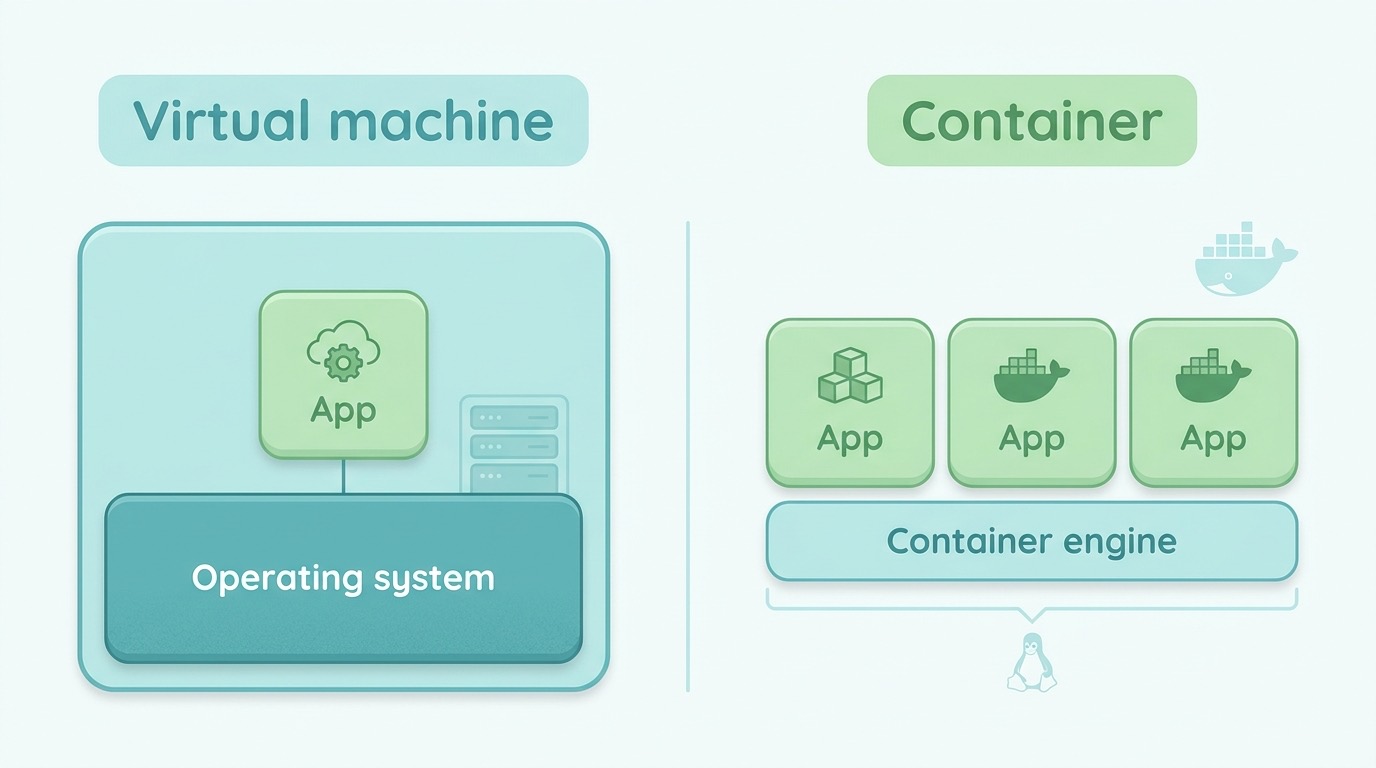
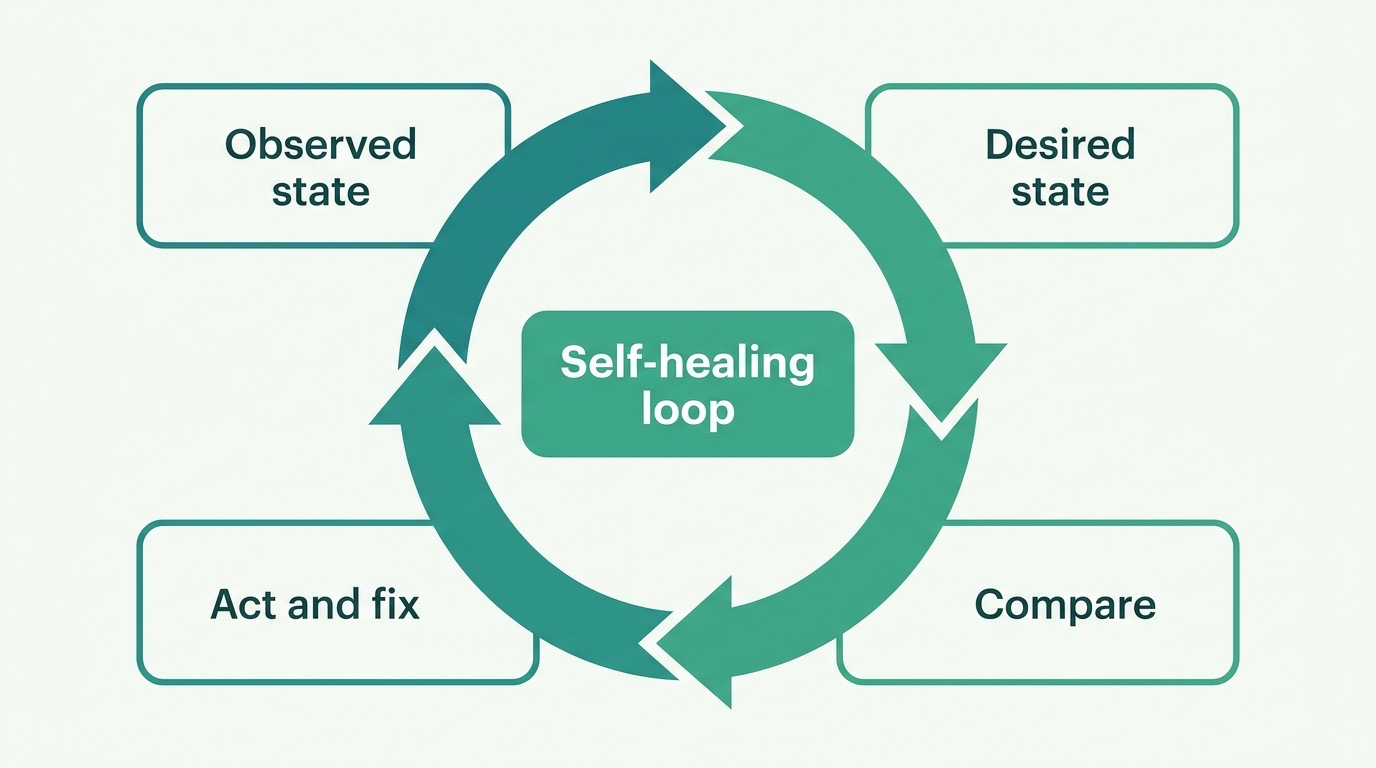
Kubernetes is de dirigent die honderden van die containers aanstuurt. Je vertelt Kubernetes niet hoe — je vertelt het wat: “ik wil altijd vier exemplaren van de website draaien.” Crasht er één, dan start Kubernetes vanzelf een nieuwe. Dat heet de reconciliation loop: het systeem vergelijkt onophoudelijk de gewenste toestand met de werkelijke, en repareert het verschil. Zelfherstel, zonder dat er iemand ‘s nachts uit bed hoeft.
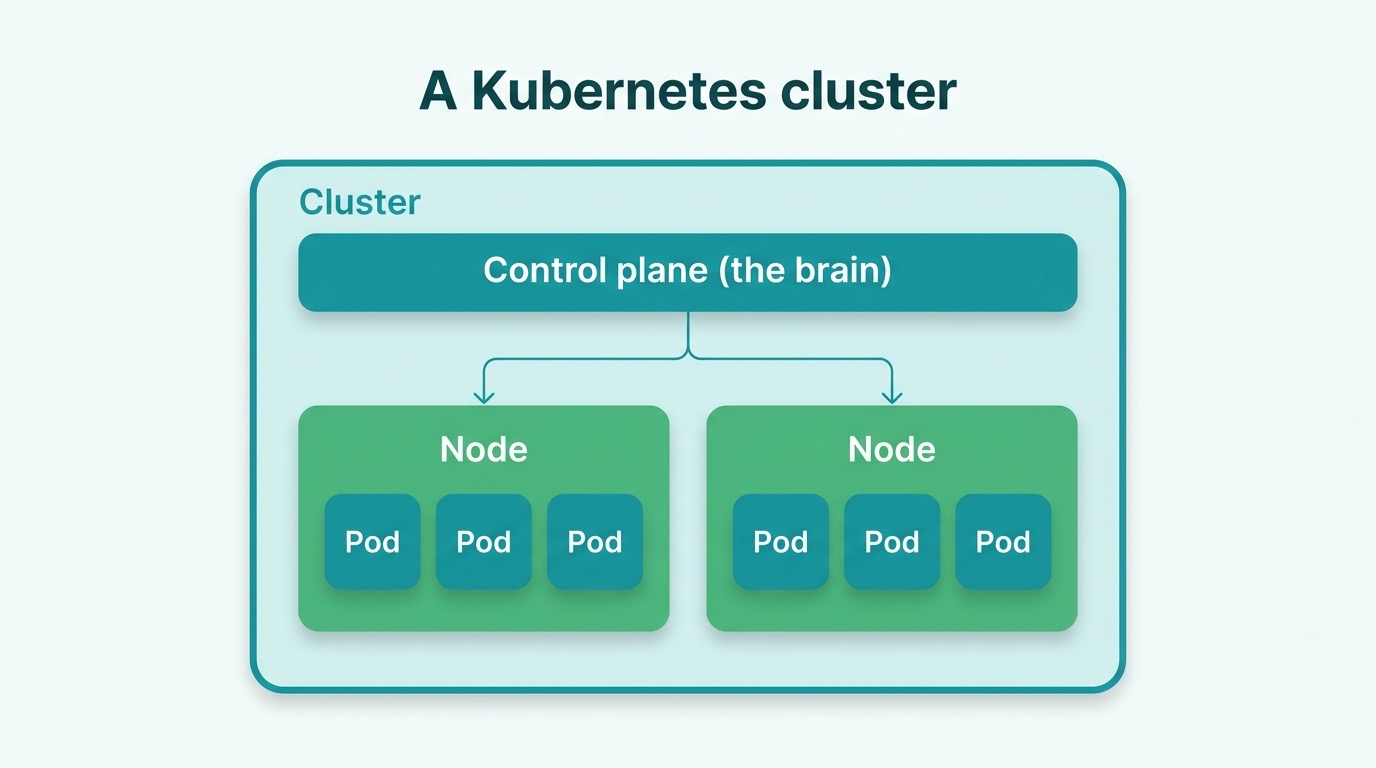
Een cluster is een groep machines waarop Kubernetes draait. Bovenin de control plane (het brein dat beslist), daaronder de nodes (de werkpaarden die de containers draaien). Wij kozen voor managed Kubernetes bij Scaleway (hun Kapsule-dienst): de control plane wordt door de provider onderhouden, wij beheren alleen de werkpaarden. Eén zorg minder.
De architectuur die we kozen
We hadden het simpel kunnen houden: één cluster, alles erin. Maar een platform dat moet meegroeien — en dat ooit een audit moet kunnen doorstaan — verdient scheiding van zorgen.
Daarom staan er nu twee clusters:
- Een gereedschaps-cluster (de gedeelde werkplaats) voor alles wat de andere clusters bedient: de build-machinerie, het centrale beheer.
- Een productie-cluster dat de echte apps draagt.
Die twee leven in gescheiden virtuele privé-netwerken (VPC’s) — drie in totaal, met een aparte ruimte gereserveerd voor ontwikkeling. De gedachte: één gecompromitteerd onderdeel mag niet automatisch bij de rest kunnen. Netwerk-isolatie is geen luxe, het is de eerste verdedigingslinie.
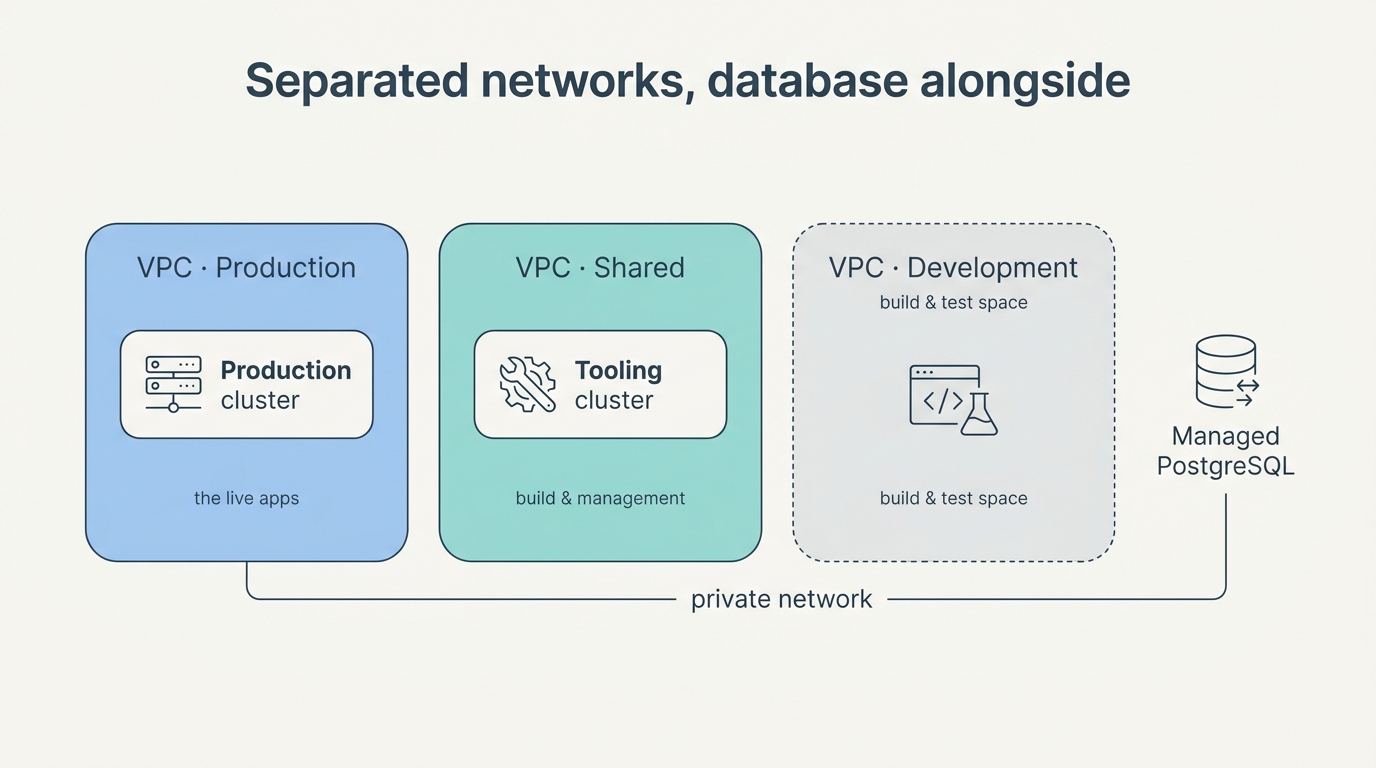
Bewust buiten het cluster: de database. Onze PostgreSQL draait als beheerde dienst ernaast, niet als container erin. Een database in een cluster is mogelijk, maar staat (letterlijke) data op het spel zodra het cluster hapert. De apps in het cluster praten over het privé-netwerk met die beheerde database — snel, en niet blootgesteld aan het publieke internet.
Van “gebouwd” naar “vanzelf live”: GitOps
Hier zit het hart van het verhaal. Hoe komt code eigenlijk in productie?
De ouderwetse manier: een engineer logt in op de server en doet iets. De moderne manier heet GitOps, en het principe is verbluffend simpel: de waarheid staat in Git. Niemand muteert het cluster met de hand. In plaats daarvan beschrijf je de gewenste toestand in bestanden in een Git-repository, en een wachter — bij ons ArgoCD — zorgt dat het cluster daar onophoudelijk naar toe beweegt. Wijkt het cluster af, dan trekt ArgoCD het terug naar wat er in Git staat.
Het mooie gevolg: élke wijziging aan productie is een Git-commit. Reviewbaar, terug te draaien, met een naam eraan. Je productiegeschiedenis is je Git-geschiedenis.
We bouwden de hele keten zó dat code volautomatisch live komt:
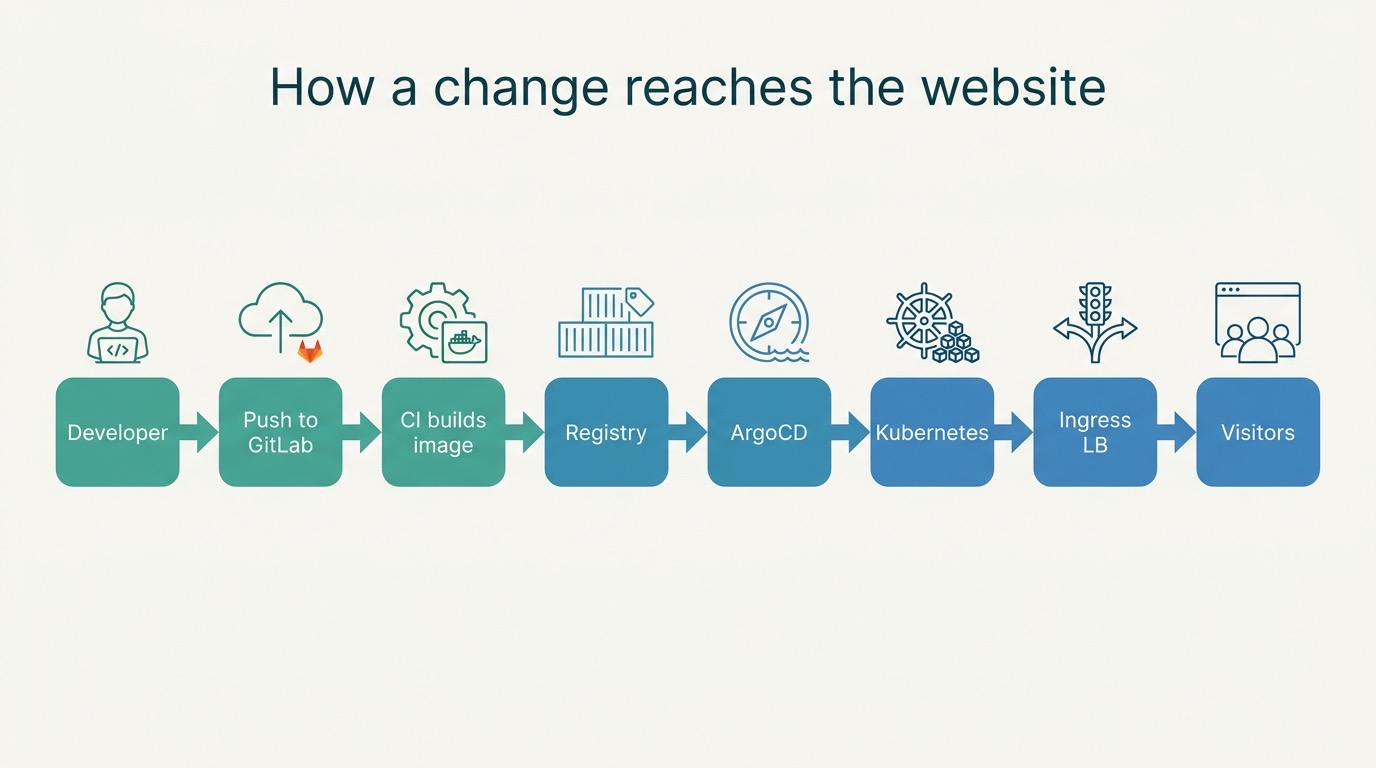
- Een wijziging wordt gemerged.
- De CI bouwt een container-image en zet ‘m in de registry.
- Een robot (de image-updater) ziet de nieuwe versie en schrijft die in een aparte branch.
- Een geplande stap opent daar automatisch een merge request voor en zet “merge zodra de tests groen zijn”.
- ArgoCD ziet de gemergede wijziging en rolt ‘m uit naar het cluster.
Tijdens het schrijven van dit stuk hebben we die keten twee keer end-to-end bewezen met echte wijzigingen: gemerged, automatisch gebouwd, gepromoot, en live op het cluster — zonder één handmatige stap. Dát is het verschil tussen “we hebben servers” en “we hebben een platform”.
Een app klaarmaken voor het cluster — en de les die pijn deed
Een applicatie verhuizen naar Kubernetes is meer dan ‘m in een container stoppen. Hij moet stateless zijn (geen data op de lokale schijf die je niet kwijt mag), z’n configuratie uit de omgeving lezen, en z’n geheimen veilig binnenkrijgen.
Dat laatste leerde ons de scherpste les van de hele migratie.
Geheimen — API-sleutels, wachtwoorden — horen niet in Git en niet in een image. Wij leveren ze via een geheimen-kluis (1Password) die door een operator in het cluster wordt omgezet naar wat de app nodig heeft. Netjes. Behalve dat de lijst geheimen tijdens de verhuizing met de hand was overgezet. En bij handwerk vergeet je dingen.
Het resultaat: een paar omgevingssleutels waren tijdens de verhuizing niet meegekomen. De webinars-pagina bleef leeg en een paar achtergrond-taken stonden uit — zónder dat de site ook maar één foutmelding toonde.
Dit is het verraderlijke aan goed gebouwde software: ze degradeert netjes. Een ontbrekende sleutel laat de site niet crashen; ze schakelt stilletjes een functie uit. Geen rode pagina, geen alarm — precies het soort gat dat je pas ziet als iemand erover struikelt.
Behalve dat wíj het wél zagen — en snel. Daar betaalde het investeren in observability zich uit. Sentry ving de eerste signalen, Inngest faalde bewust hárd in plaats van stil door te draaien, en onze eigen tests bevestigden de rest. En die meldingen verdwijnen niet in een volle mailbox: ze komen live binnen op Telegram, waar wij — mens én AI — eigenlijk altijd waken. Een deel van de signalen wordt zelfs al door een AI-wachter opgepakt die meteen een concept-fix klaarzet; ik hoef dan alleen nog te beoordelen en op de knop te drukken. Binnen de migratie-vensters opgemerkt en gedicht — niet maandenlang ongemerkt in productie.
De les die we meteen vastlegden: maak dat soort gaten lúíd in plaats van stil. We schreven een architectuurbesluit en een ticket voor een parity-gate — een controle die de uitrol laat falen zodra een verwachte sleutel ontbreekt. En de diepere les: niet “het lijkt te werken” telt, maar of je het ook écht zíét. Goede tooling — Sentry voorop, plus Inngest en echte tests — is het verschil tussen “binnen een uur gevonden” en “een klagende klant een maand later”.
Veiligheid: zo min mogelijk vertrouwen
Een platform dat publiek bereikbaar is, vraagt om discipline. De principes die we aanhielden, in gewone taal:
- Least privilege — elk onderdeel krijgt precies de rechten die het nodig heeft, niet meer.
- Netwerk-segmentatie — standaard mag niets met niets praten; verkeer wordt expliciet opengezet, niet impliciet vertrouwd.
- Geheimen nooit in Git — ze komen uit een kluis, via een operator, en raken de codebase niet.
- TLS automatisch — certificaten worden door het platform aangevraagd en vernieuwd; geen mens die een verlopen certificaat moet onthouden.
- De voordeur als één gecontroleerd punt — al het inkomende verkeer loopt via een ingress (bij ons Traefik met de Gateway API), niet via een wirwar van losse openingen.
Niets daarvan is bijzonder voor wie dit dagelijks doet. Het bijzondere is dat een platform je dwingt het zo te doen — terwijl handgevoede servers je verleiden tot “even snel”.
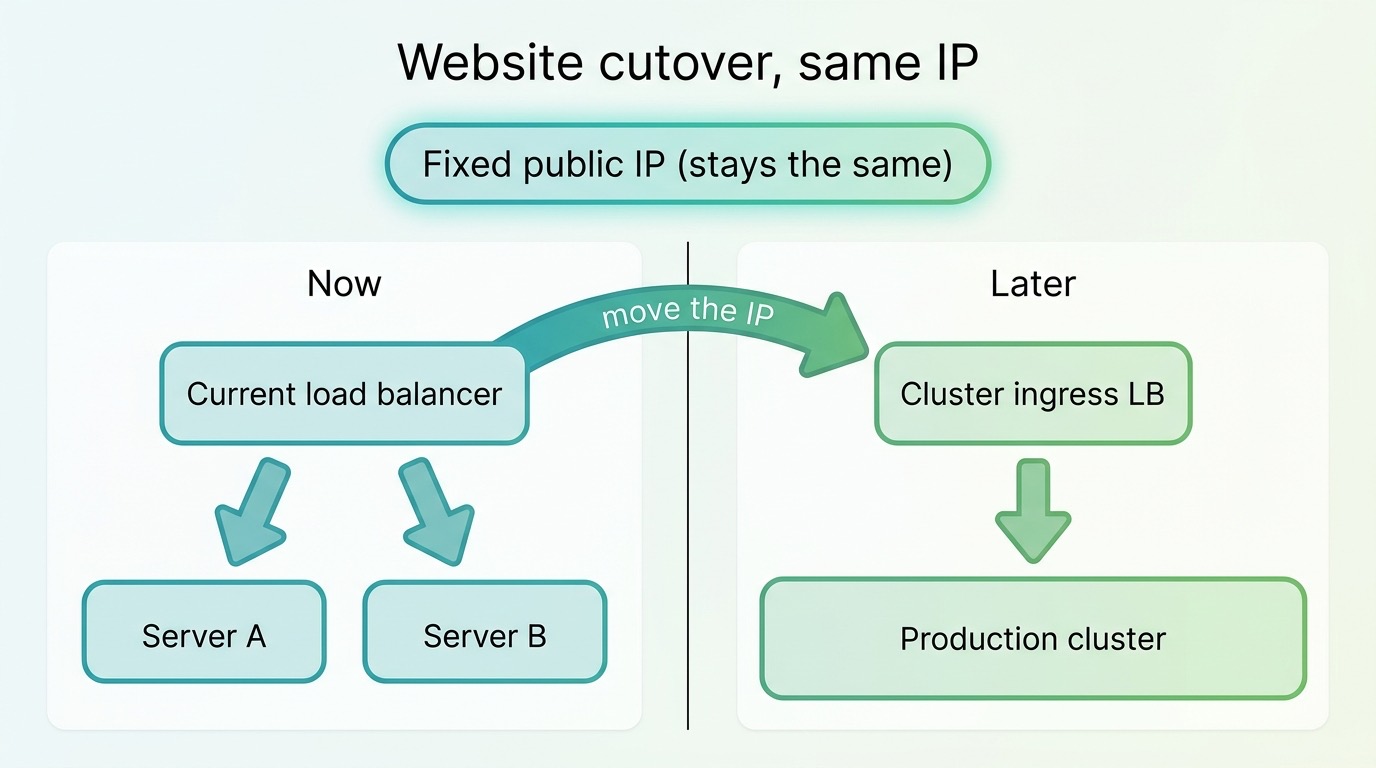
De cutover: het publieke adres blijft, alleen de bestemming verandert
De spannendste stap was de website zelf — een drukbezochte, multi-tenant applicatie — zonder downtime van de oude servers naar het nieuwe cluster verhuizen.
De truc zit in het scheiden van adres en bestemming. Het publieke IP-adres waar bezoekers en DNS naartoe wijzen, hoeft niet te veranderen. We verhuisden alleen waar dat adres naartoe leidt: van de oude load balancer naar de ingress van het cluster. Voor de buitenwereld bleef alles gelijk; intern verschoof de hele bestemming. Daarna verifieerden we laag voor laag — bereikbaarheid, geldig TLS-certificaat, databaseverbinding — en hielden we de oude servers nog even achter de hand als terugvaloptie.
Wat dit normaal kost
Tijd voor het ongemakkelijke deel — want dit is waar het verhaal pas echt landt. Wat zou het kosten om dít te laten bouwen door een ingehuurde specialist, in déze kwaliteit?
Even scherp wat “dit” is: niet één app in een container duwen, maar een compleet platform ontwerpen en bouwen (managed Kubernetes, twee clusters, gescheiden netwerken, Infrastructure-as-Code, GitOps, geheimen-beheer, automatische TLS, CI/CD, observability) én een drukbezochte productie-applicatie er zonder downtime naartoe migreren — met documentatie en architectuurbesluiten erbij.
De marktcijfers (2025–2026):
- Freelance tarieven, Nederland. Een senior DevOps/platform-engineer rekent hier al gauw €100 tot €125 per uur; een IT-/technisch architect zit volgens het Uurtarievenboekje 2025 rond de €116 per uur.12 Internationaal lopen gespecialiseerde Kubernetes-freelancers op tot $140–300 per uur.3 Een loondienst-senior in Nederland verdient €85.000–€150.000 bruto per jaar — wat die freelance-tarieven onderbouwt.4
- Een echt migratietraject. Een simpele “til één app naar Kubernetes” kan voor $15.000–50.000.5 Maar een comprehensive traject — architectuur, bouw, migratie én kennisoverdracht, precies onze scope — landt in een gepubliceerde case study op $120.000 aan alleen consulting en $239.000 totaal, over 16–20 weken met meerdere consultants.6
Vertaald naar onze situatie, eerlijk en conservatief:
Eén senior freelancer die dit netjes bouwt: ruwweg €40.000–€80.000 over twee tot vier maanden. Een gespecialiseerde consultancy die hetzelfde levert — ontwerp, bouw, migratie, overdracht: €100.000 of meer, in lijn met de gepubliceerde case studies.
En dat is niet eens het hoge scenario. Het is de ondergrens van serieus, like-for-like werk.
Wij deden het in drie dagen. ’s Nachts, in de rustige uren, naast het gewone werk. Maar voordat je dat als magie wegzet — lees vooral de volgende sectie. Want die drie dagen verdienen een eerlijke uitleg.
Waarom drie dagen kon — de fabriek, niet de auto
“Een productie-platform in drie dagen” klinkt als onzin. En als ik niet uitleg waaróm het kon, is het dat ook.
De drie dagen waren mogelijk omdat wij de negen maanden ervóór iets heel anders bouwden. Niet de auto, maar de fabriek.
In een eerder stuk schreef ik het al: bouw niet de auto, bouw de fabriek. Dat is precies wat hier gebeurde. Negen maanden lang investeerden wij niet in losse oplossingen, maar in hóé mens en AI samenwerken:
- een bibliotheek aan skills — herbruikbare werkwijzen die mijn AI-collega per taak inzet;
- een persistent geheugen — zodat context niet elke sessie verdampt en we niet telkens opnieuw beginnen;
- koppelingen naar echte systemen — een AI die niet alleen praat, maar dingen kán: servers bevragen, code uitrollen, controles draaien;
- en het minst zichtbare, en belangrijkste: werkafspraken, guardrails en vertrouwen — de gedeelde taal waarin we samen risicovolle stappen durven nemen, met de mens aan de knoppen bij alles wat telt.
Dát is de fabriek. En een fabriek die al draait, produceert snel. De migratie ging niet snel door snellere handen — ze ging snel omdat het fundament er al lag.
De AI verving dus geen team van consultants. Het was een senior-collega die naast me zat: die de architectuur uittekende, code schreef, fouten opspoorde, en me bij elke risicovolle stap dwong te bevestigen. De besluiten waren van mij. De productieknoppen drukte ik. En ik moest het zélf snappen — want ik ben degene die er morgen mee verder moet.
Daar zit de echte winst, en ze is groter dan dit ene project:
Een consultancy offreert tienduizenden tot honderdduizenden euro’s voor één migratie. Wij bouwden een herbruikbare capaciteit — de volgende migratie kost ons dagen, niet maanden. We kochten geen auto; we hebben een fabriek.
De compressie zat in het leren en het hergebruiken, niet in het overslaan. We hebben geen stap geskipt. We deden ze alleen veel sneller — omdat er altijd iemand naast me zat die het al wist, en omdat we het gereedschap om het te doen zélf hadden gesmeed.
Wat we onderweg leerden
Een paar lessen die breder gelden dan dit ene project:
- Graceful degradation verbergt gaten. Software die netjes terugvalt, verbergt fouten tot een gebruiker erover struikelt. Maak ontbrekende afhankelijkheden luid — laat de uitrol falen, niet de gebruiker.
- Een mens moet meekijken bij de laatste meter. Een geautomatiseerde controle bevestigde dat een attribuut “live” stond — maar pas toen een mens in een echte browser klikte, bleek het gedrag niet te kloppen. Automatisering en een menselijke blik vullen elkaar aan; geen van beide is genoeg.
- Eén sjabloon voor alle apps. Wat we voor de eerste app bouwden, willen we niet per app overdoen. De winst van een platform is herhaalbaarheid — dus de keten wordt een herbruikbaar patroon.
- De gedeelde database is een gedeeld risico. Zolang de oude en de nieuwe wereld dezelfde database delen, kan een uitrol in de ene wereld de andere even raken. Scheiding van zorgen is nooit “af”.
- Vee, geen huisdieren — ook in je hoofd. De grootste verandering was niet technisch maar mentaal: stop met servers verzorgen, begin met systemen beschrijven.
Waar het nu staat
Het platform draait. De drukbezochte website is live op het productie-cluster, met geldig TLS en een database-verbinding over een privé-netwerk. De uitrol-keten is twee keer end-to-end bewezen. De geheimen-gaten zijn gedicht en de structurele verbetering (de parity-gate) staat als besluit en ticket klaar. De oude servers staan nog even als vangnet, tot we zeker weten dat alles stabiel is.
En er ligt een routekaart: de uitrol-keten generaliseren tot één herbruikbaar patroon voor álle apps, de oude servers uitfaseren, en de kwaliteits- en beveiligingscontroles centraal afdwingen.
Maar de kern is binnen. Van vier handgevoede huisdieren naar een zelfherstellend platform — gebouwd door een autodidact en zijn AI-collega, in drie dagen, bovenop negen maanden fundament, met begrip van elke laag.
Dat laatste is geen bijzaak. Het is het hele punt.
En misschien is het ook het begin van een nieuw soort vak. Niet de specialist die alles zelf kan, maar iemand die — samen met AI — een fabriek bouwt en die laat draaien. Daarover een andere keer meer.
— Wim Tilburgs & Kamal
Woordenlijst
- Container — een applicatie plus haar afhankelijkheden, ingepakt in één draagbaar, dun blok.
- Kubernetes — het systeem dat containers aanstuurt en de gewenste toestand bewaakt.
- Cluster — een groep machines waarop Kubernetes draait (een brein + werkpaarden).
- Node — één werkpaard-machine in een cluster.
- Control plane — het brein van het cluster dat beslissingen neemt.
- GitOps — de werkwijze waarbij Git de waarheid is en het cluster daar automatisch naartoe beweegt.
- ArgoCD — de wachter die het cluster synchroon houdt met Git.
- Ingress — de gecontroleerde voordeur waarlangs al het inkomende verkeer loopt.
- Reconciliation loop — de onophoudelijke vergelijking van gewenste versus werkelijke toestand.
- Stateless — een app die geen onmisbare data lokaal bewaart en dus inwisselbaar is.
- VPC — een virtueel privé-netwerk dat onderdelen van elkaar isoleert.
- Least privilege — het principe dat elk onderdeel zo min mogelijk rechten krijgt.
Over de gebruikte technologie
Wil je dieper graven in de bouwstenen? De gezaghebbende bronnen:
- Kubernetes — de officiële documentatie. Het “pets versus cattle”-idee komt oorspronkelijk van Randy Bias; lees de geschiedenis van de analogie en pets vs. cattle in de Kubernetes-wereld.
- Scaleway Kubernetes Kapsule — de managed-Kubernetes-dienst die wij gebruiken (met een regio in Amsterdam). Zie de service-definitie — Scaleway beheert de control plane — en de FAQ, waarin staat dat nodes gewoon vervangen of herstart mogen worden: vee, geen huisdieren.
- GitOps & Argo CD — Argo CD, de wachter die het cluster onophoudelijk synchroon houdt met Git.
- Claude Code — de agentic coding-tool van Anthropic die als senior-collega naast me werkte: leeft in de terminal, begrijpt de codebase, voert taken uit.
Bronnen
Footnotes
-
TechPays — Netherlands, DevOps contract rates (freelance senior DevOps ~€85–105/uur; dataset met beperkt aantal datapunten, indicatief). https://techpays.com/europe/netherlands/eng_devops/contract ↩
-
Xolo / Knab Uurtarievenboekje 2025 — overzicht freelance-uurtarieven Nederland (IT-/technisch architect ~€116/uur), gebaseerd op een enquête onder ~20.000 zzp’ers. https://blog.xolo.io/nl/freelance-hourly-rates-insight-into-the-netherlands ↩
-
Jobbers — DevOps & Cloud Infrastructure Freelancing Rate Guide 2026 (gespecialiseerde Kubernetes-freelancers $140–300/uur). https://www.jobbers.io/devops-cloud-infrastructure-freelancing-aws-kubernetes-sre-rate-guide-2026/ ↩
-
Asanify — Hiring DevOps Engineers in the Netherlands 2025 (senior €85.000–120.000, lead/principal €110.000–150.000+ bruto per jaar). https://asanify.com/blog/hiring-in-netherlands/hire-devops-engineers-in-netherlands-2025/ ↩
-
Tasrie IT — Kubernetes Migration Cost (2025 Price Breakdown) (eenvoudige migratie $15.000–50.000, sterk scope-afhankelijk). https://tasrieit.com/blog/kubernetes-migration-cost-2025-price-breakdown ↩
-
Tasrie IT — case study comprehensive Kubernetes-migratie ($120.000 consulting, $239.000 totaal, 16–20 weken, meerdere consultants). https://tasrieit.com/case-studies/253k-saved-kubernetes-migration-consultants-case-study ↩